Apache Hadoop
The Apache Hadoop software project is an open-source framework for distributed processing of large data sets across clusters of computers.
This job step creates an HBase database table:
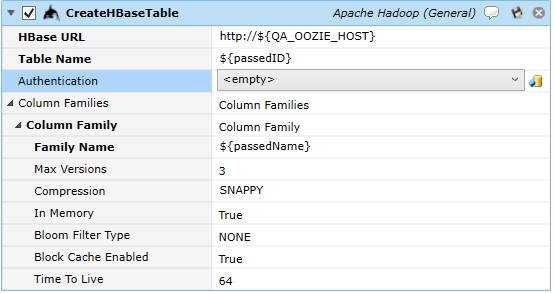
Job Step Properties
HBase URL – This property represents the URL for the HBase REST URL in the form of HTTP://hostname.com:port. If only a host is specified, the port number of 20550 is assumed.
Table Name – This property is the name of the table to be created.
Authentication – This property represents the credentials to be used when creating the table. If omitted, the jobs logged in credentials are used; if Kerberos Username Password Authentication is selected then the following pair of properties: Domain and Credentials are expected to be completed and used for table creation.
Column Families – This collection of properties represents a column in the table. You can add columns multiple column definitions by pressing the “Add” button.
Family Name - This mandatory property is the name of the column.
Max Versions - This property represents the maximum number of row versions to store.
Compression - This property represents the compression algorithm to use. Selections are: GZ, SNAPPY, LZ4. You simply enter the compression algorithm string.
In Memory - This Boolean property indicates whether the data is to be cached in memory for the longest period of time. True indicates the data should be cached.
Bloom Filter Type - Bloom filters enabled can help improve performance and reduce read latencies. Bloom filters help identify whether a row and column combination exists in a block without having to reload it.
Block Cache Enabled - This Boolean property allows you to cache blocks in memory after they’ve been read.
Time to Live - The value (in seconds) causes HBase to automatically delete rows once the expiration time has been reached.
This job step deletes an HBase database table.
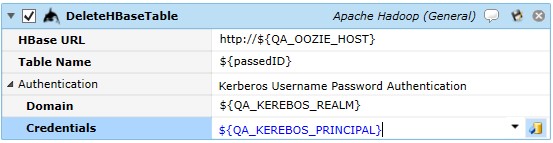
Job Step Properties
HBase URL – This property represents the URL for the HBase REST URL in the form of HTTP://hostname.com:port. If only a host is specified, the port number of 20550 is assumed.
Table Name – This property is the name of the existing table to be deleted.
Authentication – This property represents the credentials to be used when deleting the table. If omitted, the jobs logged in credentials are used; if Kerberos Username Password Authentication is selected then the following pair of properties: Domain and Credentials are expected to be completed and used for table deletion.
This job step retrieves the schema for the specified HBase Table.
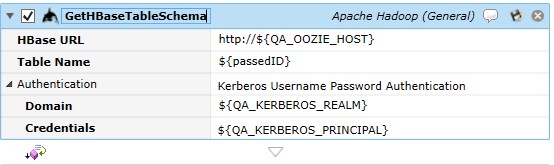
Job Step Properties
HBase URL – This property represents the URL for the HBase REST URL in the form of HTTP://hostname.com:port. If only a host is specified, the port number of 20550 is assumed. Table Name – This property is the name of the existing table.
Authentication – This property represents the credentials to be used when accessing the table. If omitted, the jobs logged in credentials are used; if Kerberos Username Password Authentication is selected then the following pair of properties: Domain and Credentials are expected to be completed and used for table access.
Return Step Values
Name – This property is the name of the table.
IsMeta – This Boolean property is true if the table is an hbase:meta table.
(http://hbase.apache.org/book.html#arch.catalog.meta – section 65.2 for explanation of what the meta table is) Columns – This collection of columns provided information on each column.
This job step allows you to issue a Hive Query. The Hive Query (HQL) is similar to a T-SQL or PL/SQL statement in that you can specify other verbs besides SELECT (for example, INSERT, UPDATE, DELETE, etc).
The examples below illustrate a simple row insertion followed by a query to retrieve the data.
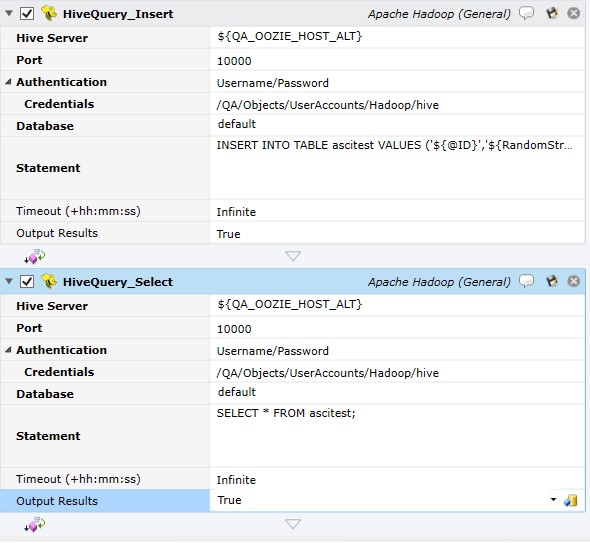
Job Step Properties
HBase URL – This property represents the URL for the HBase REST URL in the form of HTTP://hostname.com:port. If only a host is specified, the port number of 20550 is assumed.
Table Name – This property is the name of the existing table.
Authentication – This property represents the credentials to be used when accessing the table. If omitted, the jobs logged in credentials are used; if Kerberos Username Password Authentication is selected then the following pair of properties: Domain and Credentials are expected to be completed and used for table access.
Database – This property represents the Hive database to access. The dropdown allows for enumeration of the Hive Server provided the required properties have been specified.
Statement – This property is the HQL query or statement to be executed. Only a single HQL query can be specified.
Timeout – This property represents the amount of time to wait for the HQL execution to complete before failing. The default is “Infinite” (no timeout) or a value specified in hh:mm:ss).
Output Results – This Boolean property allows you to direct any output results to be written to the job’s log file. Note that you will normally want this property set to False since a lot of data being returned would then also be present in the log file.
Return Step Value
Rows – This collection of properties is returned on a successful operation. The following properties are returned: Count, IsReadOnly, IsSynchronized and SyncRoot. For a query (i.e. SELECT) you can retrieve the individual column or field elements within each row by using the FOR-EACH-ITEM job step and passing the collection (using the =collection syntax). Assuming the execution variable Row contains the actual row of data, individual elements can be accessed as %{Row[“field-name”]}.
This job step allows you to execute a Pig script.
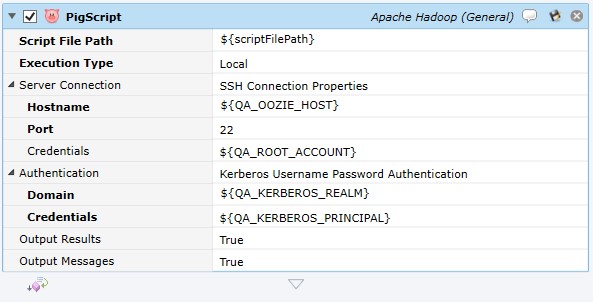
Job Step Properties
Script File Path – This property represents a file specification to the Pig script. The syntax is file:///file-specification.
Execution Type – This dropdown property indicates whether the Pig script should be executed on the local machine or Hadoop cluster. Choices are: Local and MapReduce.
Server Connection – This set of properties represents the Hadoop Hostname, Port and Credentials. The connection is performed using SSH so the port number will normally be 22. The Credentials represent the path to a User Account object representing a valid account for the execution machine.
Authentication – This set of properties represent the authentication credentials for the Hadoop cluster and Kerberos.
Output Results – This Boolean property indicates whether any script output should also be written to the job’s log file.
Output Messages – This Boolean property indicates whether any Pig execution messages should be written to the log file.
This job step exports data from HDFS.
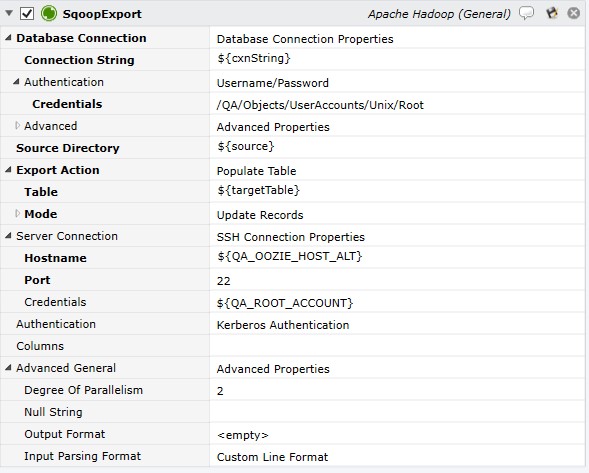
Job Step Properties
Database Connection - This set of properties contains the JDBC Connection String to the database as well as Authentication credentials and advanced properties. The Connection String syntax is jdbc:mysql://localost/Hadoop-host.
Source Directory – This property represents the path in HDFS that contains the source data.
Export Action – This dropdown property indicates the action to take when exporting. Two actions are possible: Populate Table and Call Stored Procedure. For Populate Table the following properties are used: Table is the existing table to populate and Mode represents the action to take when populating records. Insert, Update or Insert, Update are possible modes. For Insert mode, the optional Staging Table property allows you to insert rows to an existing identical staging table. By default, if no staging table is present, the exported rows are inserted directly to the target Table. For Update or Update/Insert mode, the Key property represents the column used by Sqoop to update existing records in the table. Sqoop will match exported records and the target table on this value and update the matched row. A comma-separated list of columns may be specified to match on multiple columns. Note: Select the key with care since multiple records can be updated if the column selected does not contain a unique value per record. For Call Stored Procedure action, the Stored Procedure property represents a stored procedure that is called for each exported row.
Server Connection – This optional set of properties represents the connection properties to use to connect to the host via SSH. This is not required if Sqoop is installed on the Execution Agent Machine.
Authentication – This set of properties is used when executing a job on the Hadoop cluster. These credentials will be used to authenticate with Kerberos if necessary.
Note: The Username/Password option should only be used when testing as the credentials are provided in clear text. A more secure method is to use Password File and then secure the file via file protection.
Columns – This optional property controls which columns are selected for export. By default, all columns are selected for export. If specified, you can specify the columns and order of columns to be exported using a comma-separated list.
Advanced General – This optional set of advanced properties govern parallelism and file format.
This job imports data to HDFS.
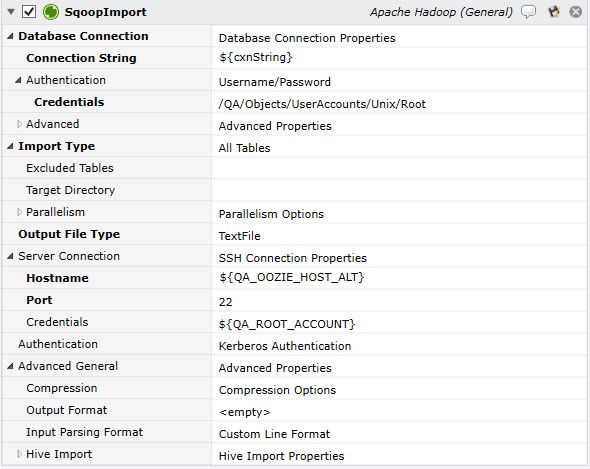
Job Step Properties
Database Connection – This set of properties contains the JDBC Connection String to the database as well as Authentication credentials and advanced properties. The Connection String syntax is jdbc:mysql://localost/Hadoop-host.
Import Type – This dropdown property indicates the action to take when importing. Two actions are possible: All Tables and Individual Table. For All Tables the following properties are used: Excluded Tables allows you to exclude specific table(s) from the import through a comma-separated list. Target Directory allows you to specify a directory in which subfolders will be created for each table. If omitted, the sub-folders are created under the user’s home directory. If Individual Table is specified, the following properties are used: Data Specification indicates where the data is to be imported, either a table or a free-form query. The parallelism sub-section allows you to override any default parallel processing with your own specification.
Server Connection – This optional set of properties represents the connection properties to use to connect to the host via SSH. This is not required if Sqoop is installed on the Execution Agent Machine.
Authentication – This set of properties is used when executing a job on the Hadoop cluster. These credentials will be used to authenticate with Kerberos if necessary. Note: The Username/Password option should only be used when testing as the credentials are provided in clear text. A more secure method is to use Password File and then secure the file via file protection.
Advanced General – This optional set of advanced properties govern compression, formatting and other Hive Import options.

This job step submits a MapReduce job.
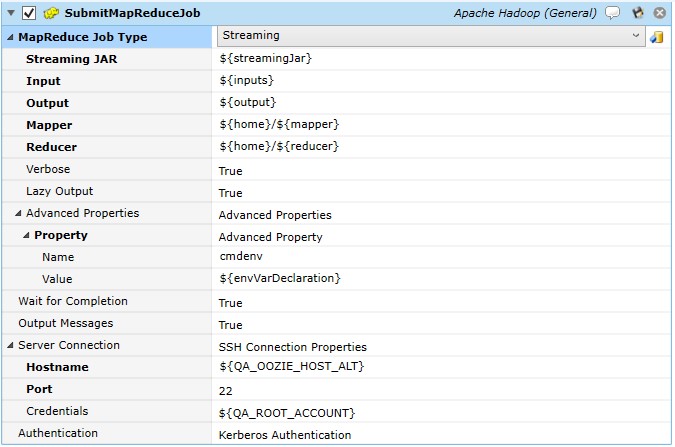
The above image depicts Submit MapReduce Job (Streaming).
Job Step Properties
MapReduce Job Type – This dropdown and collection of properties indicates whether a Streaming or Non-Streaming MapReduce job is to be submitted. Streaming denotes that the Hadoop streaming utility is used to create and run MapReduce jobs using any executable or script as the mapper and/or reducer. Non-Streaming denotes that Hadoop executes the JAR file.
Streaming
-
Streaming JAR is a property that contains the file specification for the Hadoop Streaming Jar. Wildcard specifications can be used. For example, /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming2.6.0-mr1-cdh5.8.*.jar.
-
Input represents the input location for the Mapper.
-
Output represents the output location for the Reducer.
-
Mapper represents the file specification for the location of the Mapper.
-
Reducer represents the file specification for the location of the Reducer.
-
Verbose is a Boolean property which enables/disables verbose logging.
-
Lazy Output is a Boolean property to enable/disable lazy output. Lazy Output, depending on FileOutputFormat, causes the output file to be created only on the first call to output.collect (or context.write).
-
Advanced Properties allows you to, optionally, set a series of property name/value pairs that influence and control the MapReduce job
Non-Streaming
-
JAR is the file specification for the JAR file.
-
Arguments is a collection of arguments passed to the JAR file.
Wait for Completion - This is a Boolean property that determines whether this job step waits for completion of the MapReduce job.
Output Messages - This is a Boolean property that, if Wait for Completion is enabled, causes messages generated by Mapreduce to be written to the job’s log file.
Server Connection – This optional set of properties represents the connection properties to use to connect to the host via SSH. This is not required if MapReduce is installed on the Execution Agent Machine.
Authentication – This set of properties is used when executing a job on the Hadoop cluster. These credentials will be used to authenticate with Kerberos if necessary.
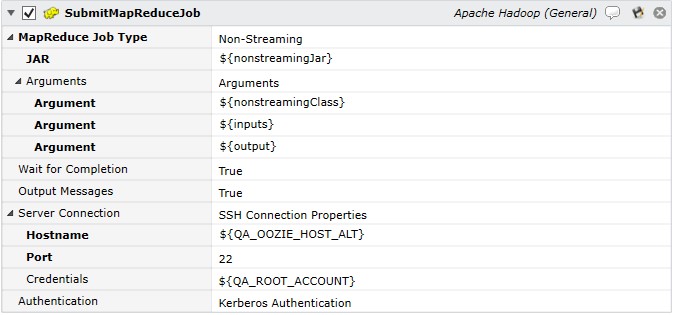
The above image depicts Submit MapReduce Job (Non-Streaming).
This job step submits a Spark application.
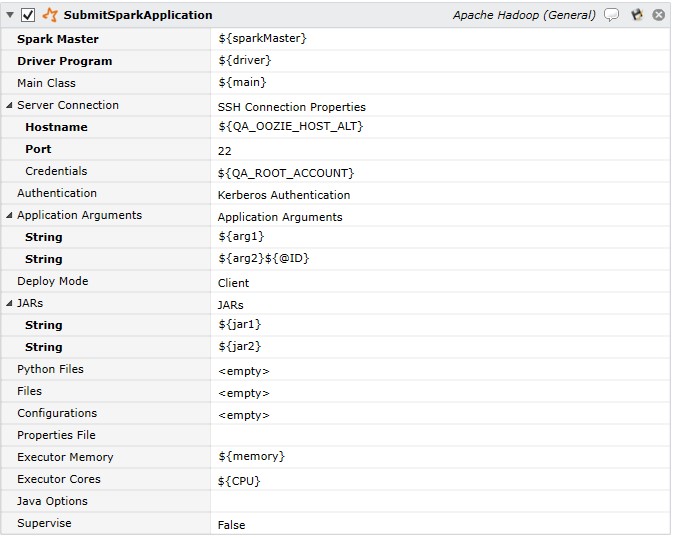
Job Step Properties
Spark Master - This property denotes the master URL for the cluster (for example, spark://10.10.10.10:7077, or local[*])
Driver Program - This is the location of the JAR app or Python script.
Main Class (optional) - This is the initial entry point for the application.
Server Connection – This optional set of properties represents the connection properties to use to connect to the host via SSH. This is not required if Spark is installed on the Execution Agent Machine.
Authentication – This set of properties is used when executing a job on the Hadoop cluster. These credentials will be used to authenticate with Kerberos if necessary.
Application Arguments - This represents zero or more arguments passed to the main method of the main class.
JARs - This is an optional list of JAR files to include on the driver and executor classpaths.
Python Files - This is an optional list of .zip, .egg or .py files to place on the PYTHONPATH for Python apps.
Files - This is an optional list of files to be placed into the working directory on each executor.
Configurations - This is an optional set of Spark Configuration properties.
Properties File - This is an optional file specification in which to load additional Spark properties.
Executor Memory - This is an optional parameter to indicate how much memory per executor.
Executor Cores - This is an optional parameter to indicate how many cores per executor. Default is 1 in YARN mode and all available in stand-alone mode.
Java Options - This is an optional parameter in which to pass extra Java options, if any.
Supervise - This is an optional Boolean property in which to denote that the driver should be restarted on failure.