![]()
Databricks (Microsoft Azure Databricks)
Databricks (formally known as Microsoft Azure Databricks) provides data science and engineering partners a powerful team-oriented platform for analytical queries against semi-structured data without a traditional database schema. Databricks allows users to trigger Databricks workflows, monitor their progress, stop and abort workflows.
ActiveBatch now supports Databricks!
You will find the new Databricks extension under Jobs Library.
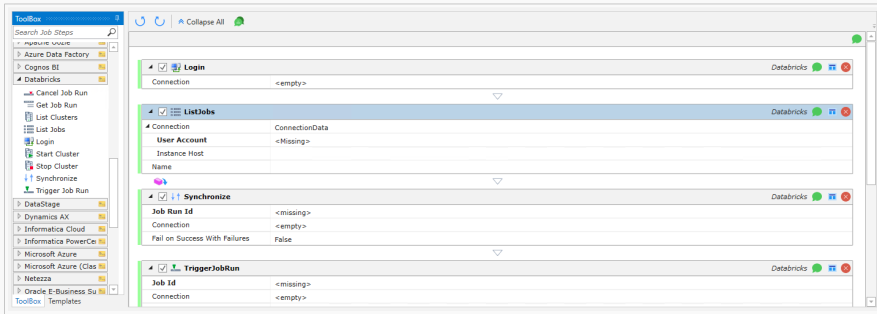
Login

Job Step Properties
Connection: Connection is optional for all Job Steps except Login. Select Connection Data from the drop-down menu and enter a User Account and
Region.
List Jobs

Retrieves a list of all jobs in the workspace.
Job Step Properties
Connection: Connection is optional for all Job Steps except Login. Select Connection Data from the drop-down menu and enter a User Account and
Region.
User Account: This is the RESTV2 OAuth User Account to connect to the Databricks instance REST API.
Instance Host: Optional. If blank, Host of Auth Token URL of the selected User Account is used.
Name: A filter on the list based on the case-sensitive job name.
Synchronize

Wait for a job run to complete before continuing.
Job Step Properties
Job Run ID: The canonical identifier of the Job Run to wait for completion before continuing.
Connection: The connection data for this Databricks instance.
Fail on Success With Failures: Boolean True or False. If True, fail the job step if it completes successfully but with some failures.
Trigger Job Run
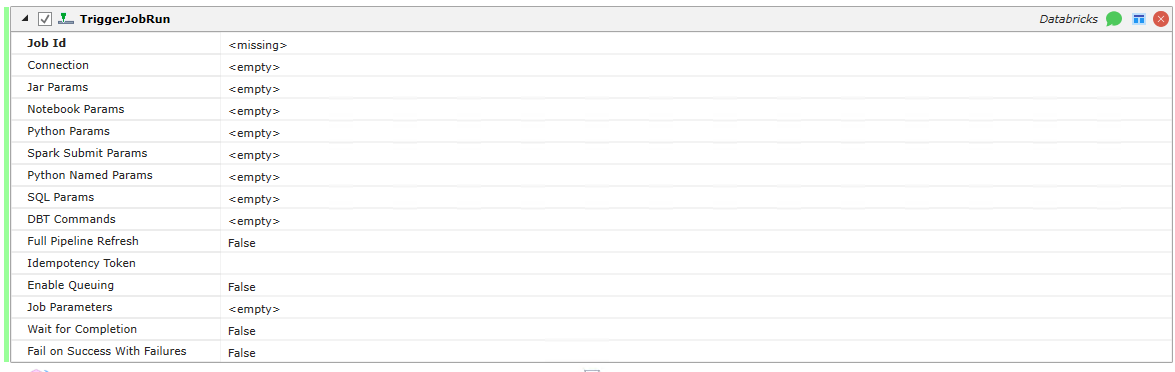
Run a job and return the run_id of the triggered run.
Job Step Properties
Job ID: The ID of the job to be executed.
Connection: Connection data for the Databricks instance.
Jar Params: A list of parameters for jobs with Spark JAR tasks.
Notebook Params: A map from keys to values for jobs with Notebook task.
Python Params: A list of parameters for jobs with Python task.
Spark Submit Params: A list of parameters for jobs with Spark Submit task.
Python Named Params:
SQL Params: A list of parameters for jobs with SQL task.
DBT Commands: An array of commands to execute with the DBT task.
Full Pipeline Refresh: Boolean True or False. If True, it triggers a full refresh on the delta live table.
Idempotency Token: An optional token to guarantee the running of the same job run requests will be identical each time.
Enable Queuing: Boolean True or False. If True, queuing is enabled.
Job Parameters: The Job-level parameters for this Job Run. If any Job Parameters are defined here, all other parameters are ignored.
Wait for Completion: Boolean True or False. Waits until the job run has been completed.
Fail on Success With Failures: Boolean True or False. If True, fail the job step if it completes successfully but with some failures.